On Feature Learning in Structured State Space Models
Publication
NeurIPS 2024. Oral and runner-up for best paper award at ICML NGSM Workshop 2024.
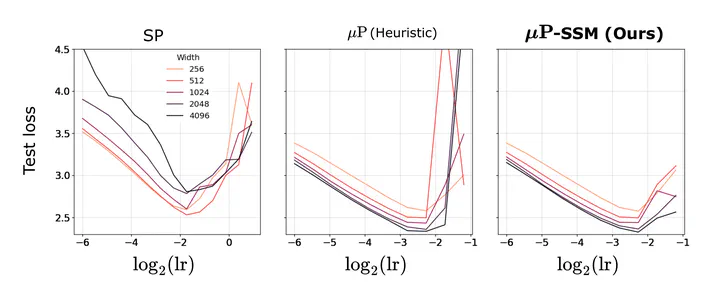
Naively scaling standard neural network architectures and optimization algorithms loses desirable properties such as feature learning in large models (see the Tensor Program series by Greg Yang et al.). We show that for the popular Mamba architecture, the traditional scaling rules like the maximal update parameterization and its related spectral scaling condition fail to induce the correct scaling properties, due to Mambas structured Hippo matrix and its selection mechanism. We derive the correct scaling using random matrix theory that necessarily goes beyond the Tensor Programs framework.