How to Scale Mixture-of-Experts: From μP to the Maximally Scale-Stable Parameterization
* Equal first author, † Equal contributor.
Despite the dominance of Mixture-of-Experts (MoE) architectures in frontier LLMs, there is no principled understanding of how hyperparameters should scale with width, expert width, number of experts, sparsity, and depth. We analyze three scaling regimes via a novel Dynamical Mean Field Theory (DMFT) of MoE training dynamics, and for each derive the unique μP prescription satisfying all maximal-update desiderata. We then show that μP does not reliably induce monotonic improvement or robust learning-rate transfer in MoEs, tracing these failures to scale-dependent aggregation dynamics. This motivates a refined notion of maximal scale stability, which we believe to be the more general set of desiderata beyond muP across architectures and optimizers. We consequently derive the Maximally Scale-Stable Parameterization (MSSP) for both SGD and Adam in all 3 MoE scaling regimes, and show recovered consistent learning rate transfer and monotonic improvement from small to large scale in both MLP and Transformer MoEs. Overall, this provides a complete, principled scaling prescription for MoE architectures as a function of width, depth, expert width, and number of experts.
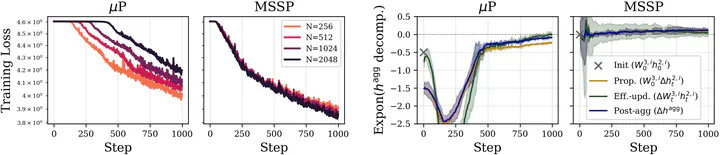
Concerning the above figure: Training with SGD on TinyImageNet, scaling width, expert width and number of experts proportionally. Delayed learning in $\mu$P due to vanishing initial terms in the MoE aggregation operation. This is resolved by sharing initial expert weights (which results in our parameterization called MSSP), and monotonic improvement with scale is recovered.
But note that there is no ‘universally valid’ benign MSSP scaling rule across different co-scaling regimes of width, expert width and number of experts; different regimes require their own solutions. For example, when fixing expert width and co-scaling width and number of experts proportionally, instead of weight sharing, MSSP is attained by increasing the initialization variance of the expert output layer. See the paper for all details.