mup^2: Effective Sharpness Aware Minimization Requires Layerwise Perturbation Scaling
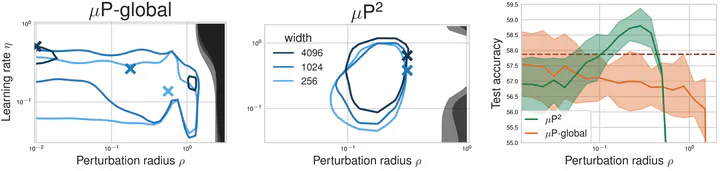
Naively scaling up standard neural network architectures and optimization algorithms loses desirable properties such as feature learning in large models (see the Tensor Program series by Greg Yang et al.). We show the same for sharpness aware minimization (SAM) algorithms: There exists a unique nontrivial width-dependent and layerwise perturbation scaling for SAM that effectively perturbs all layers and provides in width-independent perturbation dynamics.
Crucial practical benefits of our parameterization mup^2 include improved generalization, training stability and transfer of optimal learning rate and perturbation radius jointly across model scales - even after multi-epoch training to convergence. This allows to tune and study small models, and train the large model only once with optimal hyperparameters.